 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Tool-Integrated Policy Optimization
Oct 06, 2025



Large language models (LLMs) increasingly rely on multi-turn tool-integrated planning for knowledge-intensive and complex reasoning tasks. Existing implementations typically rely on a single agent, but they suffer from limited context length and noisy tool responses. A natural solution is to adopt a multi-agent framework with planner- and worker-agents to manage context. However, no existing methods support effective reinforcement learning post-training of tool-integrated multi-agent frameworks. To address this gap, we propose Multi-Agent Tool-Integrated Policy Optimization (MATPO), which enables distinct roles (planner and worker) to be trained within a single LLM instance using role-specific prompts via reinforcement learning. MATPO is derived from a principled credit assignment mechanism across planner and worker rollouts. This design eliminates the need to deploy multiple LLMs, which would be memory-intensive, while preserving the benefits of specialization. Experiments on GAIA-text, WebWalkerQA, and FRAMES show that MATPO consistently outperforms single-agent baselines by an average of 18.38% relative improvement in performance and exhibits greater robustness to noisy tool outputs. Our findings highlight the effectiveness of unifying multiple agent roles within a single LLM and provide practical insights for stable and efficient multi-agent RL training.
100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models
May 01, 2025The recent development of reasoning language models (RLMs) represents a novel evolution in large language models. In particular, the recent release of DeepSeek-R1 has generated widespread social impact and sparked enthusiasm in the research community for exploring the explicit reasoning paradigm of language models. However, the implementation details of the released models have not been fully open-sourced by DeepSeek, including DeepSeek-R1-Zero, DeepSeek-R1, and the distilled small models. As a result, many replication studies have emerged aiming to reproduce the strong performance achieved by DeepSeek-R1, reaching comparable performance through similar training procedures and fully open-source data resources. These works have investigated feasible strategies for supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR), focusing on data preparation and method design, yielding various valuable insights. In this report, we provide a summary of recent replication studies to inspire future research. We primarily focus on SFT and RLVR as two main directions, introducing the details for data construction, method design and training procedure of current replication studies. Moreover, we conclude key findings from the implementation details and experimental results reported by these studies, anticipating to inspire future research. We also discuss additional techniques of enhancing RLMs, highlighting the potential of expanding the application scope of these models, and discussing the challenges in development. By this survey, we aim to help researchers and developers of RLMs stay updated with the latest advancements, and seek to inspire new ideas to further enhance RLMs.
Panda LLM: Training Data and Evaluation for Open-Sourced Chinese Instruction-Following Large Language Models
May 04, 2023



This project focuses on enhancing open-source large language models through instruction-tuning and providing comprehensive evaluations of their performance. We explore how various training data factors, such as quantity, quality, and linguistic distribution, influence the performance of instruction-tuned models trained on publicly accessible high-quality instruction datasets for both English and Chinese languages. Our goal is to supplement evaluation with quantitative analyses, providing valuable insights for the continued advancement of open-source chat models. Our model, data, and code are publicly available for others to use and build upon.
Fast Graph Generation via Spectral Diffusion
Nov 19, 2022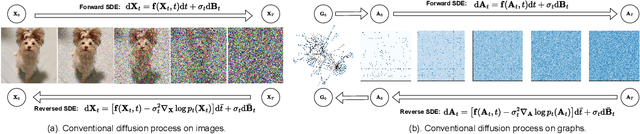
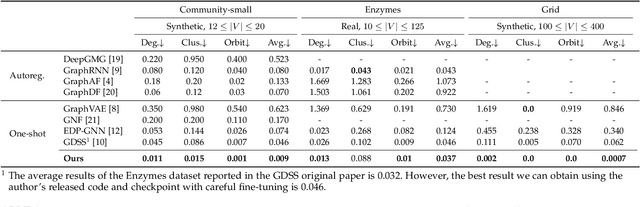
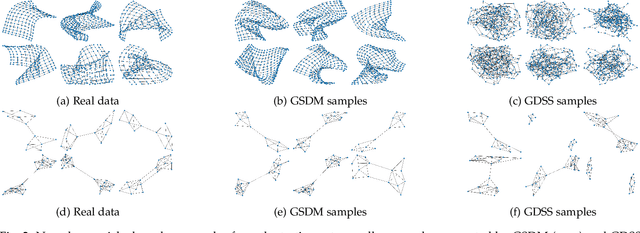

Generating graph-structured data is a challenging problem, which requires learning the underlying distribution of graphs. Various models such as graph VAE, graph GANs, and graph diffusion models have been proposed to generate meaningful and reliable graphs, among which the diffusion models have achieved state-of-the-art performance. In this paper, we argue that running full-rank diffusion SDEs on the whole graph adjacency matrix space hinders diffusion models from learning graph topology generation, and hence significantly deteriorates the quality of generated graph data. To address this limitation, we propose an efficient yet effective Graph Spectral Diffusion Model (GSDM), which is driven by low-rank diffusion SDEs on the graph spectrum space. Our spectral diffusion model is further proven to enjoy a substantially stronger theoretical guarantee than standard diffusion models. Extensive experiments across various datasets demonstrate that, our proposed GSDM turns out to be the SOTA model, by exhibiting both significantly higher generation quality and much less computational consumption than the baselines.